人工知能(LLM)を駆使した広告運用マシンをα版につき大幅割引でご提供します*α版につき、定員に達し次第締め切ります。


宣伝失礼しました。本編に移ります。
「コンバージョン測定の精度を高めたい」「膨大な検索クエリレポートの分析を効率化したい」「特定の条件に合致するページにだけ広告タグを設定したい」
獲得型広告の運用において、このような課題に直面することは少なくありません。日々膨大なデータを扱う中で、手作業による設定や分析には限界があり、時間的なコストだけでなく、ヒューマンエラーのリスクも常に伴います。これらの課題を解決し、広告運用の精度と効率を飛躍的に向上させる強力な武器が「正規表現」です。
正規表現と聞くと、プログラマーが使う難解な記号の羅列というイメージを抱くかもしれませんが、その本質は「文字列のルールを定義する」という非常にシンプルなものです。一度その基本的な使い方を習得すれば、これまで手作業で何時間もかかっていた作業を瞬時に完了させたり、不可能だと思っていた複雑な条件設定を実現したりすることが可能になります。
本記事では、広告運用者が明日からすぐに実践で使える正規表現の知識を、基礎から応用まで網羅的に解説します。メタ文字と呼ばれる特殊な記号の役割を一つひとつ丁寧に解説するのはもちろん、Googleアナリティクス(GA4)やGoogleタグマネージャー(GTM)といった必須ツールでの具体的な設定方法、さらには広告レポート分析に役立つ実践的なパターンまで、豊富な事例を交えて紹介します。記事の最後には、作成した正規表現を安全にテストできるチェッカーツールも紹介しますので、ぜひ最後までご覧いただき、貴社の広告運用を一段上のレベルへと引き上げてください。
広告運用における正規表現とは?その本質と役割

正規表現とは、文字列の集合を一つの形式で表現するための手法です。「メタ文字」と呼ばれる特殊な意味を持つ記号と、通常の文字を組み合わせて「パターン」を作成し、そのパターンに合致(マッチ)する文字列を検索、抽出、置換することができます。
例えば、広告のランディングページとして「/products/item-a/」「/products/item-b/」「/products/item-c/」…といった複数のURLがあったとします。これらのURL群を分析対象としたい場合、正規表現を使えば「/products/item-.*/」という単一のパターンで、すべてのURLを一度に指定することが可能です。
このように、メタ文字の組み合わせを工夫することで、特定のURL群を抜粋したり、膨大な検索クエリの中から特定のキーワードを含むものだけを抽出したりと、多岐にわたる文字列操作を自動化できます。手作業での確認や抽出と比較して、処理の漏れや間違いがなく、データ量がどれだけ増加しても安定して同じルールを適用できるため、再現性と正確性が求められる広告運用業務において、正規表現は不可欠なスキルと言えるでしょう。
獲得型広告の成果を最大化する、正規表現活用の4大メリット
正規表現を広告運用に導入することで、単なる時短に留まらない、多岐にわたるメリットを享受できます。ここでは、特に獲得型広告の成果に直結する4つの主要なメリットについて、具体的に解説します。
メリット1:圧倒的な作業効率化と工数削減

正規表現がもたらす最大のメリットは、何と言っても作業の劇的な効率化です。指定した条件と合致する膨大な量の文字列を、一回の操作で正確に検索・抽出・置換できるため、これまで手作業で行っていた多くの業務を自動化できます。
例えば、以下のような作業にかかる時間を大幅に削減可能です。
- レポート分析:数万行に及ぶ検索クエリレポートから、特定の製品名や型番、地域名を含むクエリだけをフィルタリングする。
- URLリスト作成:サイト内の特定のディレクトリ(例:/blog/)に存在する全ページのリストを、サイトマップやクローラーツールから一括で抽出する。
- コンバージョン設定:「/cart/thanks.php?order_id=12345」のように、購入ごとにURLが動的に変わるサンクスページを、単一のパターンで指定して計測する。
- 入稿データ作成:広告文やキーワードのCSVファイル内で、特定の記号(例:全角スペース)を半角スペースに一括で置換する。
これらの作業を手作業で行う場合、データの量に比例して時間と手間が増大し、見落としや誤操作のリスクも高まります。正規表現を活用することで、これらの定型業務に費やしていた時間を、より戦略的な分析や施策立案といったコア業務に振り向けることが可能になります。
メリット2:複雑な条件指定を簡潔かつ正確に表現

正規表現は、複雑な文字列の並びや条件を、非常に簡潔なパターンで表現できるという大きな利点があります。これにより、設定内容の可読性が高まり、管理が容易になります。
例えば、「東京支店」または「大阪支店」に関連するキャンペーンをGoogleアナリティクスで分析したい場合を考えてみましょう。正規表現を使わない場合、フィルタを2つ作成する必要があります(「キャンペーン名に『東京支店』を含む」AND「キャンペーン名に『大阪支店』を含む」)。一方、正規表現を使えば、「東京支店|大阪支店」という一つのパターンで、両方を含むキャンペーンを抽出できます。
以下の表は、URLの末尾に「dejima」から始まる任意の文字列が含まれるページ群を指定する場合の比較です。
| 正規表現を活用した場合 | 手作業(個別指定)で表す場合 |
| /dejima.* | /dejima-service /dejima-product /dejima-price (など、対象URLをすべて列挙) |
手作業の場合は対象となるすべてのURLを一つひとつ列挙する必要があり、ページが追加されるたびに設定を見直さなければなりません。一方、正規表現を用いれば「/dejima.*」と記述するだけで済みます。この簡潔さは、設定内容を一目で把握できる視認性の高さにつながり、後から設定を見直す際や、他の担当者へ引き継ぐ際の負担を大幅に軽減します。
メリット3:ヒューマンエラーの削減と設定の標準化
広告運用の現場では、コンバージョンタグの設定ミスや、レポートのフィルタリング条件の間違いといったヒューマンエラーが、時として深刻な機会損失につながります。特に、手作業による煩雑な設定やデータ処理は、エラーの温床となりがちです。
正規表現は、こうしたヒューマンエラーを防止する上でも極めて有効です。例えば、Googleタグマネージャーで10個の異なるサンクスページにコンバージョンタグを設定するケースを考えてみましょう。手作業で10個のトリガーを作成すると、URLのコピー&ペーストミスや、一部のURLの設定漏れといったエラーが発生しやすくなります。しかし、正規表現を用いて10個のURLに共通するパターンを定義し、一つのトリガーで管理すれば、設定は一度で済み、ミスが入り込む余地を大幅に減らすことができます。
また、正規表現によるルール化は、設定の標準化にも貢献します。チーム内で「製品詳細ページは『^/products/.+』というパターンで定義する」といったルールを共有しておけば、誰が設定しても同じ基準でデータ計測や分析が行えるようになり、属人化を防ぎ、組織全体のデータガバナンスを強化することができます。
メリット4:手動では不可能な高度なデータ分析の実現
正規表現を使いこなすことで、通常の管理画面の機能だけでは実現が難しい、より高度で深いデータ分析が可能になります。
例えば、検索クエリの分析において、以下のようなニーズに対応できます。
- 指名検索と非指名検索の分類:自社名やサービス名(およびその揺らぎ)を含むクエリを「指名検索」、それ以外を「非指名検索」として分類し、それぞれのパフォーマンスを正確に比較分析する。
- 潜在層のニーズ抽出:「〇〇 使い方」「〇〇 比較」「〇〇 おすすめ」といった、購入意欲の異なるユーザー層が利用するキーワードパターンを抽出し、それぞれに最適化された広告文やランディングページの効果を検証する。
- 型番検索のグルーピング:「ABC-100」「ABC-200」のような型番検索クエリを、「ABC-\d+」というパターンでまとめてグルーピングし、製品シリーズ全体の検索動向を把握する。
これらの分析は、Googleアナリティクスやスプレッドシートの関数と正規表現を組み合わせることで実現可能です。手作業での分類が事実上不可能な膨大なデータの中から、意味のあるインサイトを抽出し、次のアクションにつなげる。正規表現は、データドリブンな広告運用を実践するための強力な分析ツールとなるのです。
【最重要】広告運用で頻出する正規表現メタ文字 完全ガイド
ここからは、正規表現の根幹をなす「メタ文字」について、広告運用で特によく使われるものを厳選し、それぞれの役割と具体的な使い方を詳しく解説します。一つひとつの意味を正確に理解することが、正規表現を使いこなすための第一歩です。
- 「^」「$」:特定の語句による行頭と行末を指定する
- 「|」:前後に指定したいずれかの文字列(OR条件)を指定する
- 「[]」:囲まれた文字のうちのいずれか1文字を指定する
- 「.」:改行を除く任意の1文字を指定する
- 「*」「+」「?」:直前の文字の繰り返し回数を指定する
- 「()」:複数の文字列をグループ化する
- 「\」:メタ文字をただの文字として扱う(エスケープ)
これらのメタ文字を順番に見ていきましょう。
「^」「$」:文字列の位置(行頭・行末)を精密に指定する

特定の語句で「始まる」文字列を指定したい場合はメタ文字の「^」(ハット、キャレット)を、「終わる」文字列を指定したい場合は「$」(ドル)を使用します。これらは、マッチさせる文字列の位置を限定する際に極めて重要です。
以下の表に、GoogleアナリティクスでページのURLパスを指定する際の入力例を記載しました。
| 正規表現 | マッチするURLパスの例 | マッチしないURLパスの例 |
| ^/dejima | /dejima /dejima/labo |
/service/dejima |
| dejima/$ | /service/dejima/ /labo/dejima/ |
/dejima/labo/ |
| ^/dejima/$ | /dejima/ | /dejima/labo /service/dejima/ |
「^/dejima」の解説:
「^」は文字列の先頭を表します。この正規表現は、「/dejima」という文字列で始まるURLパスにマッチします。そのため、「/dejima/labo」のように後ろに別の文字列が続く場合でもマッチしますが、「/service/dejima」のように先頭以外に「/dejima」が現れるURLパスにはマッチしません。特定のディレクトリ配下のページ群をまとめて指定したい場合に多用します。
「dejima/$」の解説:
「$」は文字列の末尾を表します。この正規表現は、「dejima/」という文字列で終わるURLパスにマッチします。そのため、「/service/dejima/」のように手前に他の文字列がある場合でもマッチしますが、「/dejima/labo/」のように末尾に他の文字列が続く場合にはマッチしません。拡張子(例: .html$)や末尾の「/」の有無を厳密に指定したい場合に便利です。
「^/dejima/$」の解説:
「^」と「$」を組み合わせることで、完全一致を指定できます。この場合、「/dejima/」という文字列そのものにしかマッチしません。これは、Googleアナリティクスのフィルタで「等しい」を選ぶのと同じ効果ですが、他の正規表現と組み合わせて使う際に重要となります。
【実践での注意点】
正規表現では、特に指定がない限り「部分一致」で動作します。つまり、検索対象の文字列のどこかにパターンが含まれていればマッチしてしまいます。意図しないマッチを防ぐために、「^」や「$」を使ってマッチさせたい位置を明確に定義する癖をつけることが、正確な設定への近道です。
「|」:複数の条件のいずれか(OR条件)を指定する

「|」(パイプ、縦線)は、区切られた文字列の「いずれか」にマッチさせたい場合に使用するメタ文字です。論理演算子の「OR」と同じ意味と捉えると理解しやすいでしょう。複数のキャンペーンやキーワード、地域などをまとめて扱いたい場合に非常に便利です。
以下の表に、正規表現で「tokyo|osaka|nagoya」と表した場合の例を挙げました。
| 正規表現 | マッチするキャンペーン名の例 |
| tokyo|osaka|nagoya | campaign_tokyo_search display_osaka_new nagoya_campaign_2025 |
「tokyo|osaka|nagoya」という正規表現は、「tokyo」「osaka」「nagoya」のいずれかの文字列を含むキャンペーン名にマッチします。これにより、複数の地域向けキャンペーンのパフォーマンスを一度にフィルタリングして確認できます。
【実践での注意点】
「|」は非常に強力ですが、意図しない範囲にマッチしてしまうことがあります。例えば、「apple|apple pie」という正規表現で「apple pie」を検索すると、「apple」の部分だけでマッチが成立してしまいます。より長い文字列を優先的にマッチさせたい場合は、「apple pie|apple」のように長い方を先に書くか、後述するグルーping「()」と組み合わせるなどの工夫が必要です。
「[ ]」:文字の集合の中からいずれか1文字を指定する

メタ文字の「[]」(角括弧)は、角括弧で囲まれた中の「いずれか1文字」にマッチします。文字のバリエーションを吸収したい場合に有効です。
以下の表に、「[abc]」と「[abc]de」という2つの正規表現の例を挙げました。
| 正規表現 | マッチする文字列の例 |
| [abc] | "a"pple, "b"anana, "c"at の中の太字部分 |
| [abc]de | ade, bde, cde |
「[abc]」は「a」「b」「c」のいずれか1文字にマッチします。「[abc]de」と表した場合は、「a」または「b」または「c」の直後に「de」が続く文字列(ade, bde, cde)にマッチします。
ハイフン「-」による範囲指定
「[]」の中では、ハイフン「-」を使って文字の範囲を効率的に指定できます。これは広告運用で数値を扱う際によく利用されます。

| 正規表現 | マッチする対象 |
| [a-z] | 小文字の半角アルファベットのいずれか1文字 |
| [A-Z] | 大文字の半角アルファベットのいずれか1文字 |
| [0-9] | 半角数字のいずれか1文字(`\d` と同義) |
| [a-zA-Z0-9] | 半角英数字のいずれか1文字 |
例えば、「product-[0-9]」という正規表現は、「product-1」「product-2」...「product-9」にマッチします。
キャレット「^」による否定
「[]」の直後にキャレット「^」を置くと、「囲まれた文字を含まない」という否定の意味になります。これは行頭を表す「^」とは全く異なる役割なので、注意が必要です。
| 正規表現 | マッチする文字列の例 |
| [^abc] | 「a」「b」「c」以外の任意の1文字(例: "d", "1", "あ") |
この否定の機能は、特定のパラメータが付与されていないURLを除外する、といった高度なフィルタリングで役立ちます。
「.」:改行以外の任意の1文字を指定する万能カード

「.」(ドット)は、正規表現における「ワイルドカード」のような存在で、改行文字(\n)を除く、ほとんど全ての「任意の1文字」にマッチします。英字、数字、ひらがな、漢字、記号、スペースなど、文字の種類を問いません。
以下の表に「.」を活用した正規表現の例を記載しました。
| 正規表現 | マッチする文字列の例 |
| a.c | abc, a1c, aあc, a-c |
| /item/.. | /item/10, /item/ab, /item/XY |
「.」は非常に便利ですが、その万能さゆえに意図しない文字列にもマッチしてしまう危険性があります。例えば、「a.c」は「abc」だけでなく「axc」にもマッチします。もしアルファベットに限定したい場合は、「[a-z]」のように、より限定的な表現を使う方が安全です。
【最重要:エスケープの概念】
ここで非常に重要な注意点があります。もし、メタ文字としての「.」ではなく、URLに含まれる「.」(ドット)そのものにマッチさせたい場合はどうすればよいでしょうか。例えば、「example.com」にマッチさせたい場合、「example.com」と書いてしまうと、「.」が任意の1文字として解釈され、「example-com」や「exampleXcom」にもマッチしてしまいます。
これを避けるためには、メタ文字の直前に「\」(バックスラッシュ、または環境により円マーク)を置き、そのメタ文字が持つ特殊な意味を打ち消す(エスケープする)必要があります。つまり、「example\.com」と書くのが正解です。このエスケープは、正規表現を正確に扱う上で最も重要な概念の一つです。
「*」「+」「?」:直前の文字の繰り返しを指定する量指定子

「*」(アスタリスク)、「+」(プラス)、「?」(クエスチョンマーク)は「量指定子」と呼ばれ、直前の文字やグループが何回繰り返されるかを指定します。それぞれの意味は微妙に異なります。
「*」:直前の文字が0回以上繰り返す
「*」は、直前の文字が0回以上、つまり「なくてもよいし、何回あってもよい」場合にマッチします。
「+」:直前の文字が1回以上繰り返す
「+」は、直前の文字が1回以上、つまり「最低1回は必ず出現し、その後は何回続いてもよい」場合にマッチします。
「?」:直前の文字が0回または1回
「?」は、直前の文字が0回または1回、つまり「なくてもよいし、1回だけあってもよい」場合にマッチします。
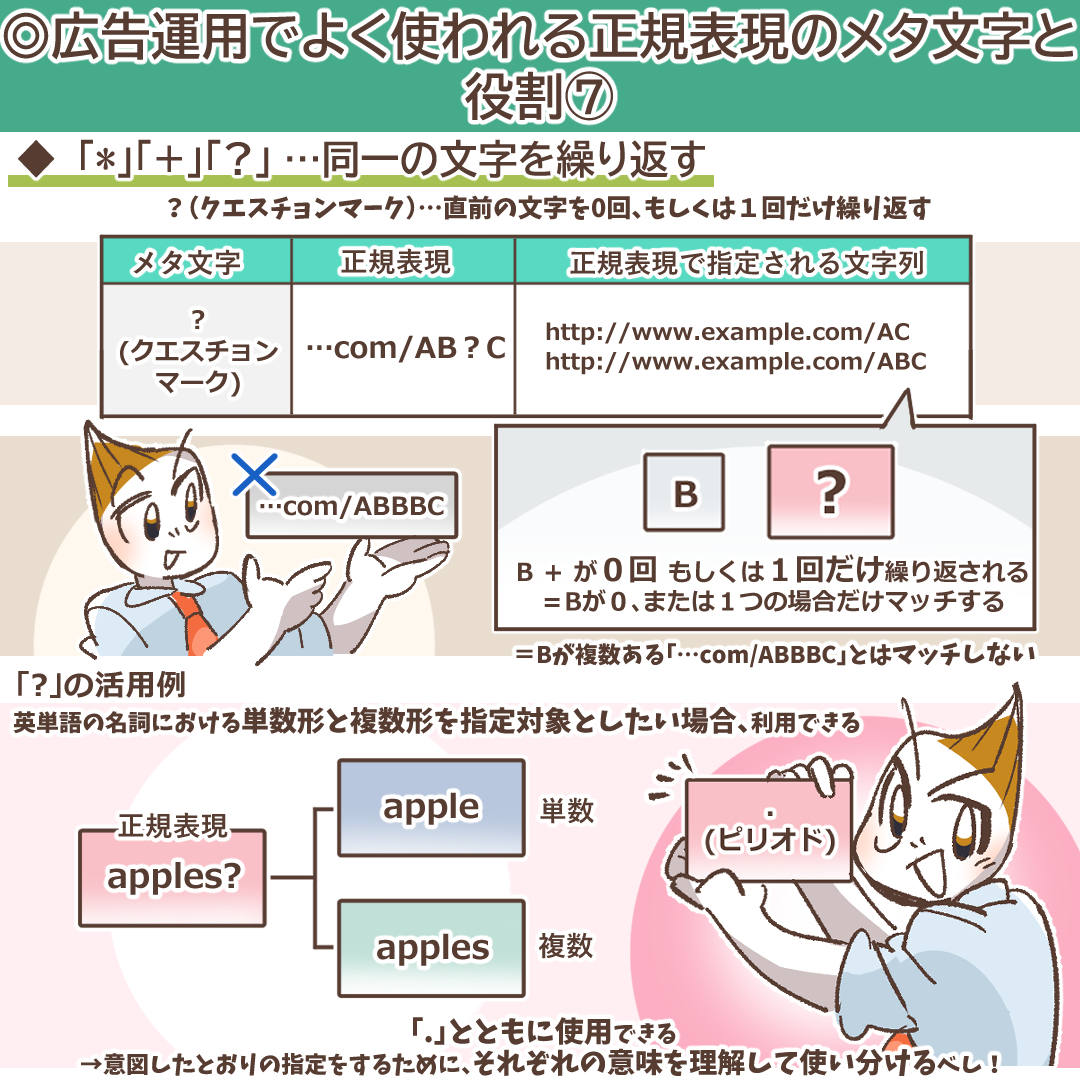
これらの違いを、正規表現「AB*C」「AB+C」「AB?C」を例に見てみましょう。
| 文字列 | AB*C (0回以上) | AB+C (1回以上) | AB?C (0回か1回) |
| AC | マッチ | しない | マッチ |
| ABC | マッチ | マッチ | マッチ |
| ABBC | マッチ | マッチ | しない |
【実践での注意点:貪欲マッチ(Greedy Match)】
「*」や「+」は、デフォルトで「貪欲(Greedy)」な動作をします。これは、マッチする可能性がある限り、できるだけ長い文字列にマッチしようとする性質です。例えば、「
」という正規表現で「
」という文字列を検索すると、最初の「
」まで、つまり「
」全体にマッチしてしまいます。
これを防ぎ、最も短い単位でマッチさせたい場合は、「非貪欲(Lazy/Non-Greedy)」な量指定子を使います。量指定子の後ろに「?」を追加することで、非貪欲になります。
- *?:0回以上の最短マッチ
- +?:1回以上の最短マッチ
先ほどの例で「
」を使うと、「
」と「
」の2つにそれぞれマッチさせることができます。この「貪欲」と「非貪欲」の使い分けは、より高度な文字列抽出において非常に重要です。
「( )」:複数の文字列のグループ化とキャプチャ
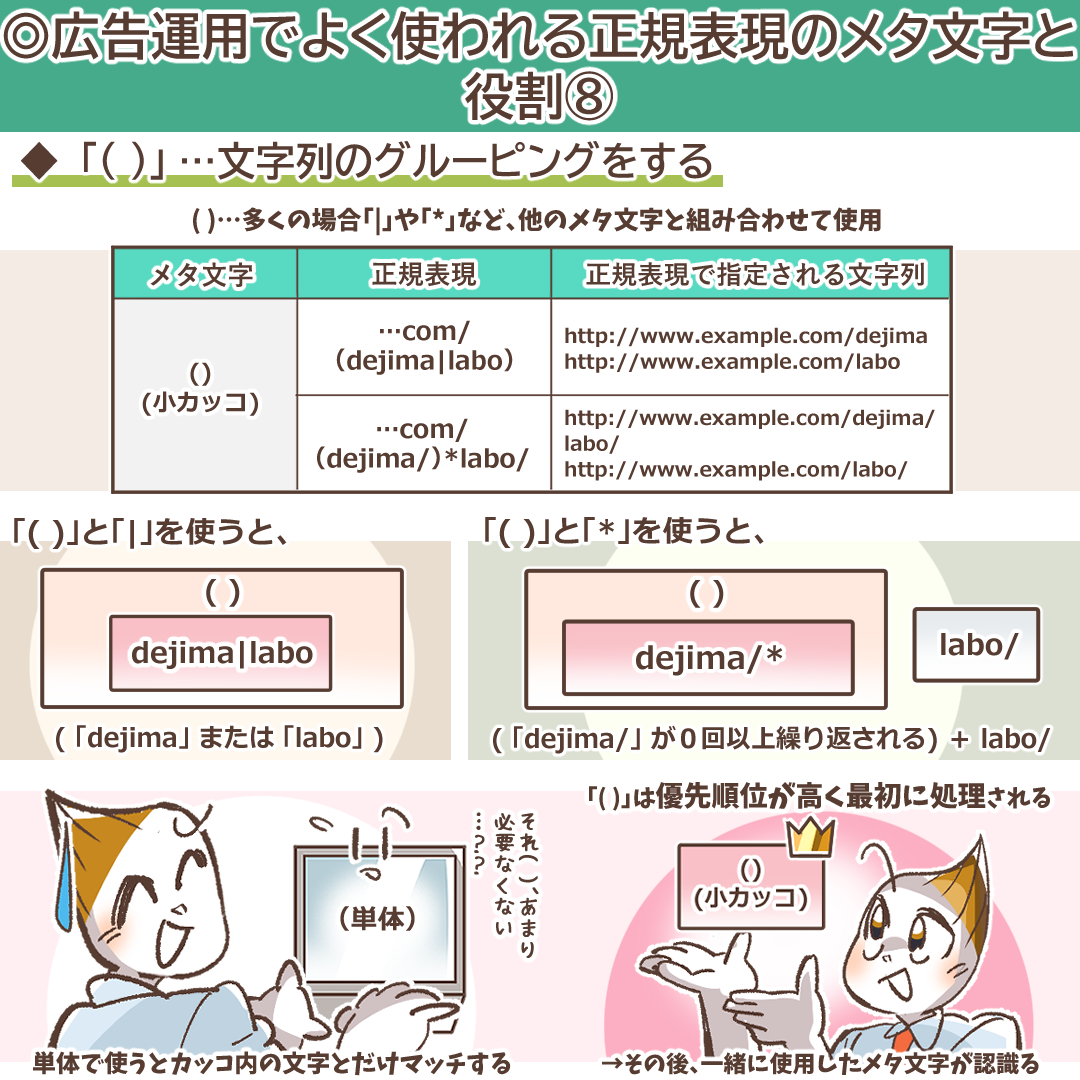
「()」(丸括弧)は、複数の文字列を一つの塊として「グループ化」する役割を持ちます。これにより、グループに対して量指定子を適用したり、「|」の適用範囲を限定したりできます。
| 正規表現 | マッチする文字列の例 |
| (dejima/)*labo/ | labo/ dejima/labo/ dejima/dejima/labo/ |
| /(dejima|labo)/ | /dejima/ /labo/ |
「(dejima/)*labo/」の解説:
この例では、「dejima/」という文字列がグループ化されています。そのグループに対して「*」(0回以上の繰り返し)が適用されているため、「dejima/」がない場合、1回ある場合、複数回ある場合のすべてにマッチします。
「/(dejima|labo)/」の解説:
もし「/dejima|labo/」と括弧なしで書くと、「/dejima」または「labo/」という意味になってしまいます。「()」で「dejima|labo」をグループ化することで、「/」と「/」の間にある「dejimaまたはlabo」という正しい意味になります。
【実践での注意点:キャプチャと非キャプチャ】
「()」には、グループ化するだけでなく、マッチした部分を「キャプチャ(記憶)」するというもう一つの重要な機能があります。これは、Googleアナリティクスのフィルタ設定やスプレッドシートの関数で、URLの一部を抜き出して再利用する際に役立ちます。
しかし、単にグループ化したいだけでキャプチャする必要がない場合もあります。その際は、「(?:...)」という形式の「非キャプチャグループ」を使用するのがベストプラクティスです。非キャプチャグループは、キャプチャグループよりも処理がわずかに高速であるため、パフォーマンスが重視される場面(特にGTMのトリガーなど)では積極的に利用することが推奨されます。
「\」:メタ文字の特殊能力を無効化するエスケープ処理
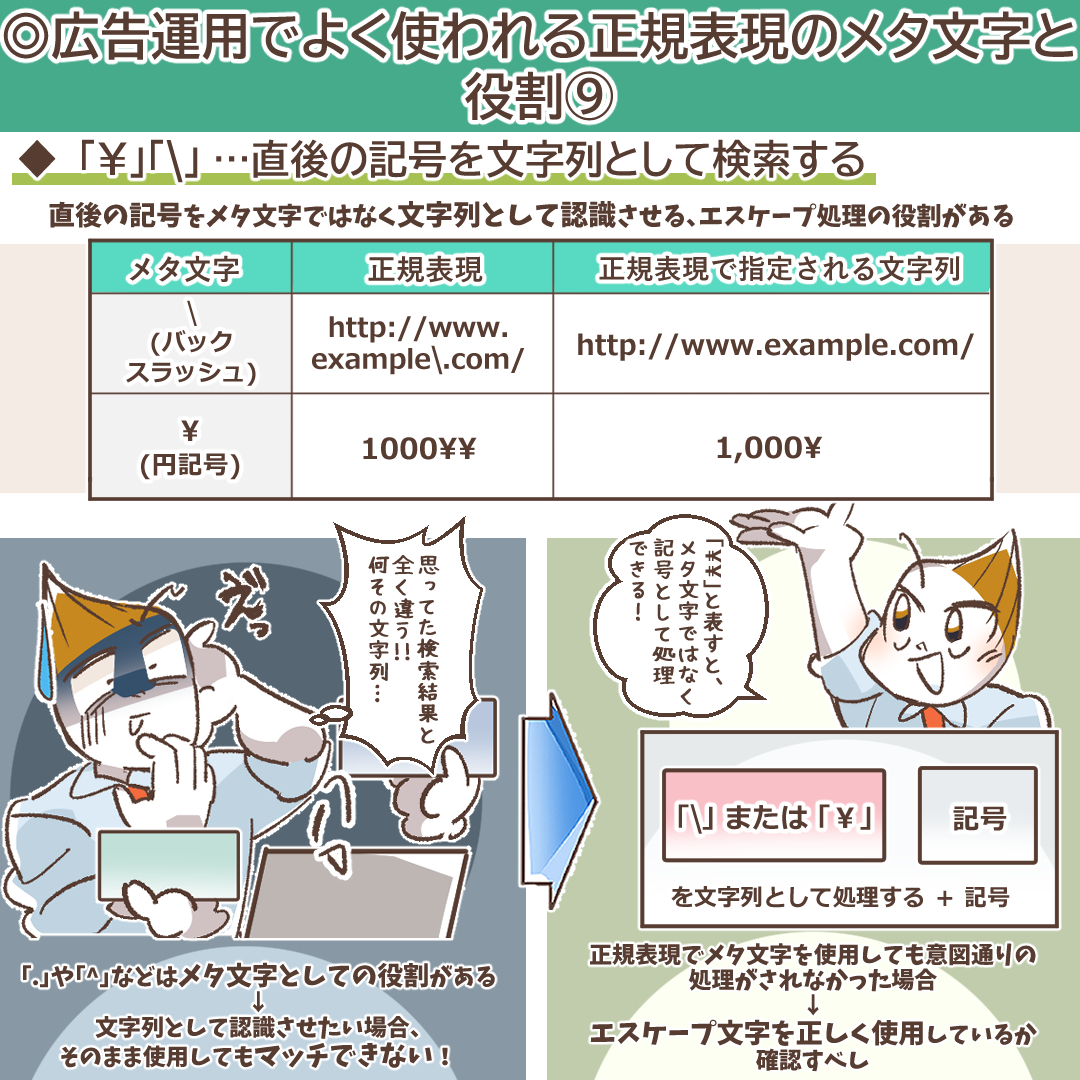
「\」(バックスラッシュ、環境によっては円記号「¥」)は、直後に続くメタ文字が持つ特殊な意味を打ち消し、単なる文字(リテラル)として扱わせるための「エスケープ文字」です。正規表現が意図通りに動かない原因の多くは、このエスケープ処理の漏れです。
広告運用で特にエスケープが必要になる文字は以下の通りです。
- . (ドット):URLのドメイン区切りなど
- ? (クエスチョンマーク):URLのクエリパラメータ開始記号
- + (プラス):キーワードのマッチタイプ記号など
- * (アスタリスク)
- ^, $, |, [], (), {}:その他のメタ文字すべて
以下の表に、エスケープ処理の具体例を記載しました。
| マッチさせたい文字列 | 誤った正規表現 | 正しい正規表現 (エスケープ後) |
| example.com | example.com | example\.com |
| /search?q=abc | /search?q=abc | /search\?q=abc |
| keyword+a | keyword+a | keyword\+a |
| \1,000 | \1,000 | \\1,000 |
「\」自体を文字としてマッチさせたい場合は、「\\」のように2つ重ねてエスケープします。
正規表現を作成する際は、「この文字はメタ文字か?それともただの文字か?」と常に自問自答し、メタ文字をただの文字として扱いたい場合は、必ず「\」でエスケープする習慣をつけましょう。これが、正確で堅牢な正規表現を作成するための最も重要な鍵となります。
【ツール別】広告運用における正規表現の活用シーンと設定方法
基礎知識を学んだところで、ここからは広告運用に不可欠なツールで正規表現を実際にどう活用するのか、具体的な設定方法を交えて解説します。Googleアナリティクス(GA4)、Googleタグマネージャー(GTM)、そしてGoogleスプレッドシートでの活用法をマスターしましょう。
1. Googleアナリティクス(GA4)での活用

GA4では、レポートのフィルタリング、セグメントやオーディエンスの作成、内部トラフィックの除外など、様々な場面で正規表現が活躍します。GA4ではマッチタイプとして「正規表現に一致」を選択することで、正規表現を利用できます。
活用シーン(a):レポートのフィルタリング
標準レポートや探索レポートで、特定の条件に合致するデータのみを表示させたい場合に正規表現は強力です。例えば、「集客 > トラフィック獲得」レポートで、特定のキャンペーン群の成果だけを見たい場合などに使用します。
設定手順:
- 対象のレポート(例:「トラフィック獲得」)を開きます。
- レポート上部の「フィルタを追加」をクリックします。
- 「ディメンションを選択」で「セッションのキャンペーン」などを選びます。
- 「マッチタイプ」で「正規表現に一致」を選択します。
- 「値」の入力欄に正規表現(例: `^(brand_a|brand_b)_.+`)を入力します。
- 「適用」をクリックします。
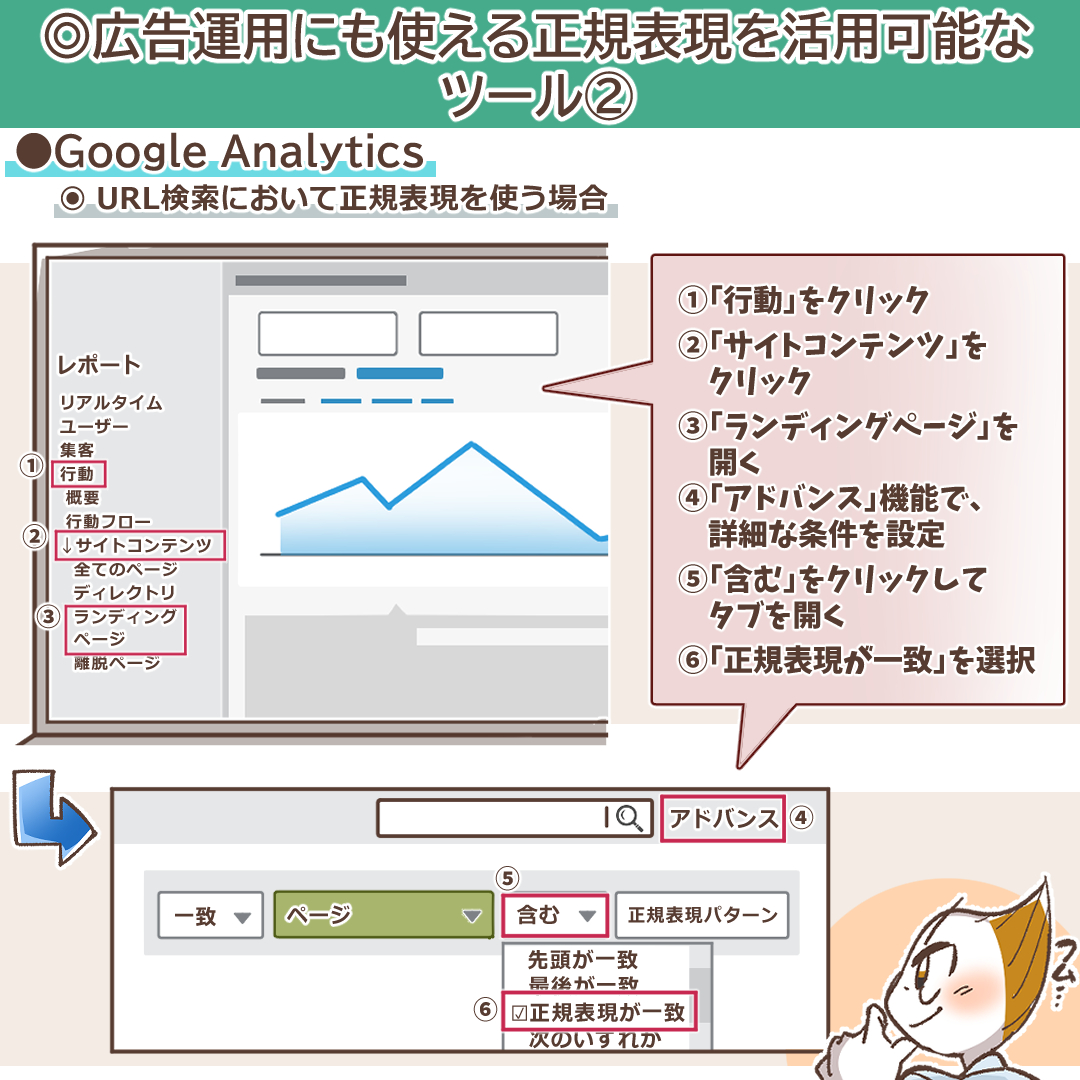
この例(`^(brand_a|brand_b)_.+`)では、「brand_a」または「brand_b」で始まり、その後に「_」と任意の文字列が続くキャンペーン(例: brand_a_search, brand_b_display)をすべて抽出できます。
活用シーン(b):オーディエンスの作成
正規表現は、リマーケティング広告の配信などに利用する「オーディエンス」を、より柔軟に作成する際にも役立ちます。例えば、特定の製品カテゴリページ(例: /products/camera/ または /products/lens/)を閲覧したユーザーをまとめてオーディエンス化できます。
設定手順:
- GA4の「管理」から「オーディエンス」を選択し、「新しいオーディエンスを作成」をクリックします。
- 「カスタムオーディエンスを作成」を選びます。
- 「新しい条件を追加」で「イベント」から「page_view」などを選択します。
- パラメータとして「page_location」(完全なURL)または「page_path」(ドメイン以下のパス)を追加します。
- フィルタ条件で「正規表現に一致」を選び、値に正規表現(例: `/products/(camera|lens)/`)を入力します。
- オーディエンス名を設定し、保存します。
これにより、複数の製品カテゴリに興味を示したユーザー群に対して、横断的なキャンペーンを展開するといった施策が可能になります。
活用シーン(c):内部トラフィックの除外
自社や関係者からのアクセスをデータから除外し、正確なユーザー行動を分析するために、IPアドレスの除外設定は必須です。オフィスが複数のIPアドレスを使用している場合など、正規表現を使うと一括で指定できます。
設定手順:
- 「管理」から「データストリーム」を選択し、対象のウェブストリームをクリックします。
- 「タグ設定を行う」の中にある「内部トラフィックの定義」をクリックします。
- 「作成」を押し、ルール名(例: 本社IPアドレス)を入力します。
- 「IPアドレス > マッチタイプ」で「正規表現に一致」を選択します。
- 「値」に、IPアドレスの範囲を示す正規表現(例: `^192\.168\.1\.\d+$`)を入力します。
- 作成後、「データフィルタ」でこのルールを有効化します。(デフォルトではテストモード)
この例では、192.168.1.0から192.168.1.255までの範囲のIPアドレスをまとめて除外対象として定義できます。(IPアドレスの「.」はエスケープが必要な点に注意)
2. Googleタグマネージャー(GTM)での活用

GTMは、広告運用において正規表現が最も真価を発揮するツールの一つです。主に、タグを配信する条件(トリガー)を設定する際に、「正規表現に一致」または「正規表現に一致しない」を利用することで、極めて柔軟なタグ管理が実現します。
活用シーン(a):複数ページでのCVタグ設定(OR条件)
商品やサービスによってサンクスページが複数存在するが、それらをまとめて一つのコンバージョンとして計測したい場合に正規表現が役立ちます。
シナリオ:以下の3つのURLをコンバージョンページとしたい。
- `https://example.com/thanks/service-a/`
- `https://example.com/thanks/service-b/`
- `https://example.com/complete/service-c/`
設定手順:
- GTMの「トリガー」で「新規」をクリックします。
- トリガーのタイプとして「ページビュー」を選択します。
- 「このトリガーの発生場所」で「一部のページビュー」を選択します。
- トリガーを発行する条件を「Page Path」「正規表現に一致」「`^/(thanks/service-(a|b)|complete/service-c)/$`」と設定します。
- トリガーに名前を付けて保存し、対象のコンバージョンタグに設定します。
この正規表現は、「/thanks/service-a/」「/thanks/service-b/」「/complete/service-c/」のいずれかのURLパスに完全に一致した場合にのみトリガーが発動することを意味します。これにより、3つのトリガーを個別に作成する手間が省け、管理が非常にシンプルになります。
活用シーン(b):特定のディレクトリ配下でのイベント計測
ブログ記事(例: /blog/ 以下)のページだけで、特定のリンククリックや滞在時間などを計測したい場合に便利です。
シナリオ:/blog/ ディレクトリ内の全ページで、外部リンクのクリックを計測したい。
設定手順:
- まず、外部リンククリックを検知するトリガーを作成します。(トリガータイプ「リンクのみ」など)
- 次に、そのトリガーがブログページでのみ発火するように、有効化条件を設定します。トリガーの設定画面の下部にある「このトリガーは以下の場合に有効になります」で条件を追加します。
- 「Page Path」「正規表現に一致」「`^/blog/.*`」と設定します。
この「有効化条件」機能を使うことで、トリガーグループのような複雑な設定をせずとも、特定のページ群でのみトリガーを有効にできます。
活用シーン(c):特定のパラメータを除外したトリガー設定
プレビューモードやテスト環境で付与される特定のURLパラメータを検知し、本番のデータに影響を与えないようにタグの発火を抑制したい場合に有効です。
シナリオ:URLに `debug=true` というパラメータが含まれている場合は、タグを発火させたくない。
設定手順:
- 対象のトリガーの設定画面を開きます。
- 条件として「Page URL」「正規表現に一致しない」「`debug=true`」と設定します。
ここでは「正規表現に一致しない」を使います。「正規表現に一致しない」は強力な除外条件として機能し、特定のパターンを含む場合にタグの発火を止めることができます。例えば、社内IPからのアクセスを除外する際などにも応用可能です。
3. Googleスプレッドシート・Excelでの活用

広告レポートの分析や、大量のキーワード・広告文を含む入稿用CSVファイルの作成・編集作業において、スプレッドシートと正規表現の組み合わせは絶大な効果を発揮します。ExcelでもVBAを使えば正規表現を扱えますが、標準関数で対応しているGoogleスプレッドシートの方が手軽に利用できます。

Googleスプレッドシートには、正規表現を扱うための専用関数が3つ用意されています。
| 関数 | 機能と使い方 |
| REGEXMATCH | 指定した文字列が正規表現にマッチするかどうかを判定し、TRUE(マッチする)またはFALSE(マッチしない)を返します。 書式:`=REGEXMATCH(テキスト, 正規表現)` 用途:検索クエリの分類(指名/非指名)、URLのパターン判定など。 |
| REGEXEXTRACT | 指定した文字列から、正規表現にマッチした部分を抽出(抜き出し)します。 書式:`=REGEXEXTRACT(テキスト, 正規表現)` 用途:URLからドメイン名や特定のパラメータ値を抽出、キャンペーン名から地域名や製品名を抽出するなど。 |
| REGEXREPLACE | 指定した文字列の中で、正規表現にマッチした部分を別の文字列に置換します。 書式:`=REGEXREPLACE(テキスト, 正規表現, 置換後のテキスト)` 用途:表記の揺れ(全角/半角など)を統一、不要な記号の削除、URLの整形など。 |
活用事例:検索クエリレポートの自動分類
ダウンロードした検索クエリレポート(A列にクエリが記載)を、「指名」「一般」「疑問」の3つに自動で分類する例を見てみましょう。
分類ルール:
- 指名:会社名「デジマ」またはサービス名「ラボ」を含む
- 疑問:「とは」「使い方」「なぜ」のいずれかを含む
- 一般:上記以外
B列に以下のIFS関数を入力します。
`=IFS(REGEXMATCH(A2, "デジマ|ラボ"), "指名", REGEXMATCH(A2, "とは|使い方|なぜ"), "疑問", TRUE, "一般")`
この数式をオートフィルで下にコピーするだけで、何万行あろうと一瞬で全クエリの分類が完了します。このように、正規表現関数と他の関数を組み合わせることで、レポート分析の工数を劇的に削減できます。
【逆引きリファレンス】広告運用者のための実践正規表現パターン集
ここでは、これまでの解説を基に、広告運用の現場で「これがやりたい」という目的別に、コピー&ペーストしてすぐに使える正規表現のパターンをリファレンス形式でまとめました。ぜひブックマークしてご活用ください。
1. URLのマッチング
| シナリオ:特定のページやページ群を指定したい | |
| やりたいこと | 正規表現パターン例(Page Pathを指定) |
| トップページのみ | `^/$` |
| `/service/` で始まるページ全て | `^/service/.*` |
| `.html` で終わるページ全て | `\.html$` |
| `/products/` と `/items/` の両方の配下にあるページ | `^/(products|items)/.*` |
| 動的にIDが変わるサンクスページ(例: /thanks.php?id=123) | `^/thanks\.php\?id=\d+$` |
2. キーワード・キャンペーン名のマッチング
| シナリオ:特定のキーワードやキャンペーンを抽出・分類したい | |
| やりたいこと | 正規表現パターン例 |
| 指名キーワード(自社名、サービス名の揺らぎを含む) | `(株式会社)?デジマ(・| )?ラボ` |
| 地域名を含む検索クエリ(東京、大阪、名古屋) | `東京|大阪|名古屋` |
| 「〇〇 比較」「〇〇 おすすめ」など検討段階のクエリ | ` (比較|おすすめ|ランキング|口コミ)$` |
| 2語の掛け合わせキーワードのみ | `^[^ ]+ [^ ]+$` |
| キャンペーン名から日付(例: 20250725)を抽出 | `(\d{8})` |
3. 除外設定
| シナリオ:特定の条件を持つものを分析対象やトリガーから除外したい | |
| やりたいこと | 正規表現パターン例(「正規表現に一致しない」で使用) |
| テストパラメータ `dev=1` が付いたURLを除外 | `dev=1` |
| 管理画面 `/admin/` を含むURLを除外 | `/admin/` |
| 特定の参照元(例: internal-site.com)を除外 | `internal-site\.com` |
【厳選】安全・高機能な正規表現チェッカー3選
正規表現は非常に強力ですが、一つの記号を間違えるだけで意図しない結果を招く可能性があります。そのため、ツールに実装する前に、必ず「チェッカー」を使ってテストすることが不可欠です。ここでは、無料で利用でき、広告運用者にとっても使いやすい高機能なチェッカーを3つ厳選して紹介します。
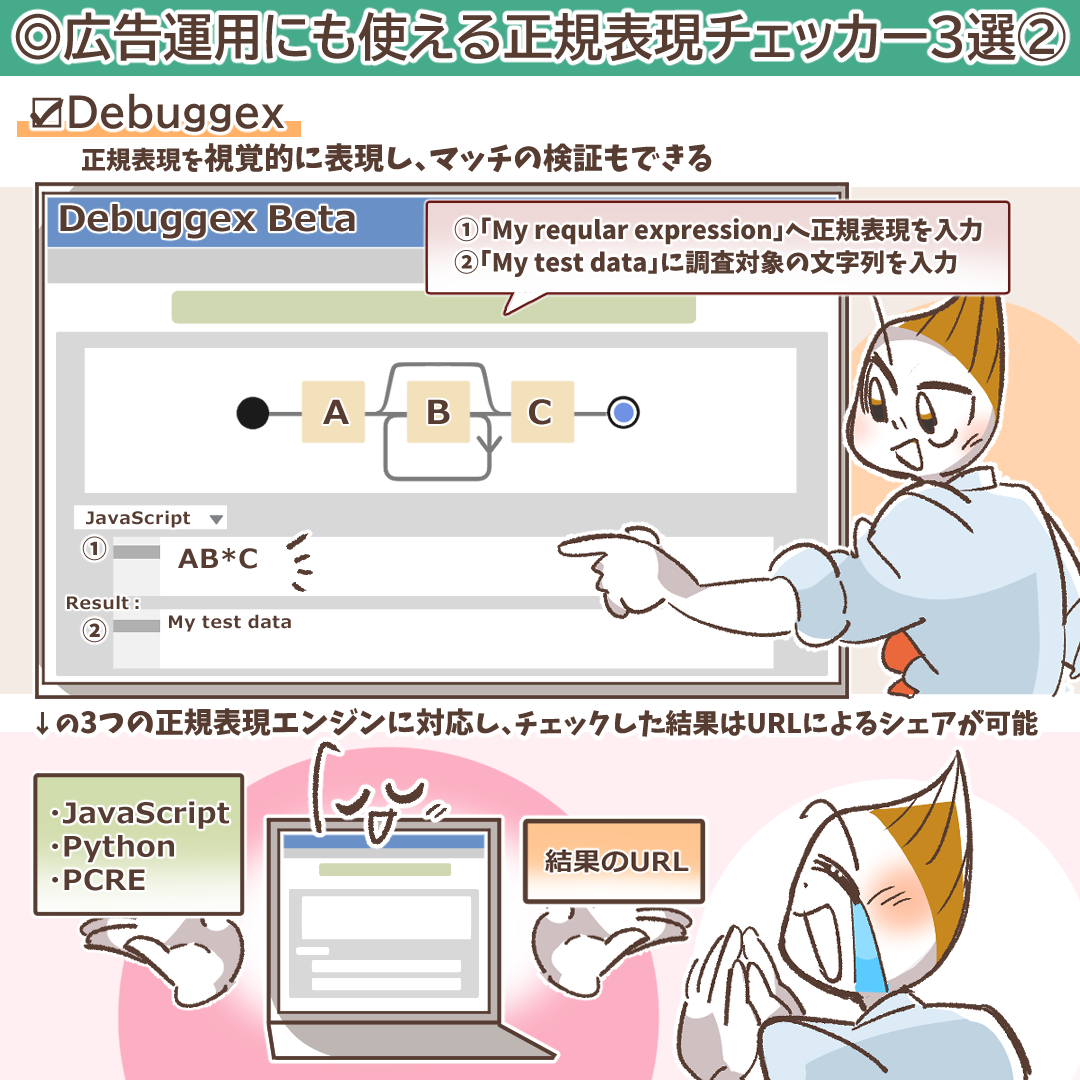
1. Regex101:最も高機能で学習にも最適
Regex101は、世界中の開発者やデータアナリストに愛用されている、事実上の標準チェッカーです。正規表現を入力すると、その意味を英語で詳細に解説してくれる機能があり、学習ツールとしても非常に優れています。どの部分がどのメタ文字によってマッチしているのかが色分けで表示されるため、複雑な正規表現のデバッグに最適です。GoogleアナリティクスやGTMで使われている「RE2」に近い「PCRE」や「JavaScript」など、複数のエンジン(Flavor)を切り替えてテストできる点も大きな魅力です。
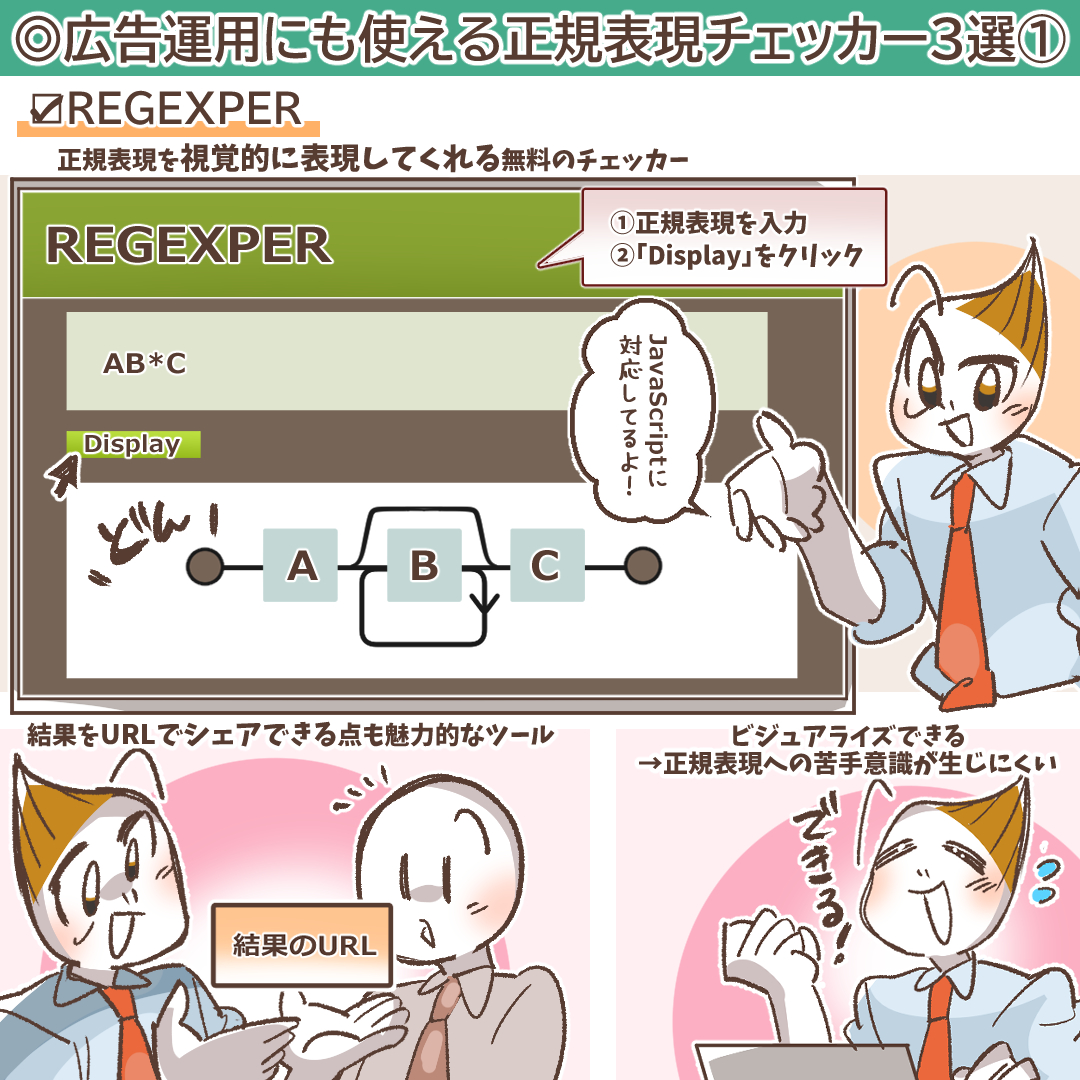
2. REGEXPER:正規表現をビジュアル化する
REGEXPERは、入力した正規表現をフローチャートのような図(ダイアグラム)に自動で変換してくれるユニークなツールです。文字列がどのような流れで判定されていくのかを視覚的に理解できるため、正規表現の構造を直感的に把握したい初心者や、複雑なパターンの全体像を確認したい場合に役立ちます。作成した図はURLで共有できるため、チーム内でのレビューにも便利です。
3. Rubular:シンプルで高速な動作

Rubularは、Ruby言語用のチェッカーですが、そのシンプルさと動作の軽快さから、多くのユーザーに支持されています。画面は非常にミニマルで、「正規表現」と「テスト文字列」を入力するだけで、リアルタイムにマッチ結果が表示されます。余計な機能がない分、素早く簡単なチェックを行いたい場合に最適です。マッチした部分がハイライト表示されるだけでなく、キャプチャグループにマッチした内容も一覧で確認できます。
まとめ:正規表現を制する者は、広告運用を制す
本記事では、獲得型広告の運用担当者が業務の精度と効率を飛躍させるための武器として、「正規表現」の基礎から応用、そして具体的な実践方法までを網羅的に解説しました。
正規表現を習得することで得られるメリットは計り知れません。
- 手作業によるデータ抽出や設定作業を自動化し、圧倒的な工数削減を実現する。
- 複雑な条件を簡潔なルールで定義し、ヒューマンエラーを防ぎ、設定管理を効率化する。
- GA4やGTMのポテンシャルを最大限に引き出し、手動では不可能な高度なデータ計測と分析を可能にする。
はじめは難解な記号の羅列に見えるかもしれませんが、本記事で紹介したメタ文字の基本的な役割を理解し、チェッカーツールを活用しながら少しずつ試していくことで、その便利さと強力さを実感できるはずです。正規表現は、一度使い方を覚えれば、広告運用業務のあらゆる場面で応用が効く、まさに一生モノのスキルです。
ぜひ、本記事を片手に、まずは簡単なURLのフィルタリングやトリガー設定から正規表現を取り入れてみてください。その一歩が、貴社の広告パフォーマンスを新たな高みへと導く、大きな飛躍につながることをお約束します。
当社では、AI超特化型・自立進化広告運用マシン「NovaSphere」を提供しています。もしこの記事を読んで
・理屈はわかったけど自社でやるとなると不安
・自社のアカウントや商品でオーダーメイドでやっておいてほしい
・記事に書いてない問題点が発生している
・記事を読んでもよくわからなかった
など思った方は、ぜひ下記のページをご覧ください。手っ取り早く解消しましょう
▼AI超特化型・自立進化広告運用マシンNovaSphere▼







